
Get started
Whisper is like a super-smart listener. It has learned from lots of different things people say, so it understands many languages and can even translate them. The big Whisper model you can use listens really well and talks back fast, especially when you ask it to listen through our special talking-to-computers tool. Both the Whisper you can use and the free one are almost the same, but the one you can use with the tool is like a race car – it talks even faster!
The speech-to-text API comprises two distinct endpoints, namely 'transcriptions' and 'translations,' leveraging our advanced open-source large-v2 Whisper model. These endpoints cater to the following functionalities:
- Transcriptions Endpoint: The 'transcriptions' endpoint facilitates the conversion of audio content into text, preserving the original language of the audio. This process involves utilizing the Whisper model's advanced speech recognition capabilities to accurately transcribe spoken content accurately, ensuring an accurate representation of the spoken words in written form.
- Translations Endpoint: The 'translations' endpoint offers a more comprehensive feature set. It not only transcribes the spoken audio but also provides translations of the transcribed content into English. This involves the sophisticated application of the Whisper model's multilingual capabilities, which include both speech recognition and language translation functionalities.
Regarding file uploads, the system accommodates files up to 25 megabytes in size. Supported input file formats encompass a range of audio file types, such as mp3, mp4, mpeg, mpga, m4a, wav, and webm.
These input files serve as the source from which the Whisper model generates transcriptions and translations. This comprehensive API infrastructure empowers developers to seamlessly harness the capabilities of the Whisper model for their speech-to-text needs, offering flexibility in handling various audio sources and linguistic requirements.

Create A New Node.js Project
First of All, install Node js in your system environment
To check the version of Node js use
Then create a project folder Name:- Speech to text
Please install the Necessary packages

In Node.js, multer is a widely used middleware that simplifies the process of handling file uploads in web applications. When building applications that require users to upload files, such as images, videos, or documents, multer provides a streamlined way to manage this functionality. It efficiently processes multipart/form data, the format commonly used for file uploads in HTML forms.

Transcription
The transcriptions API takes as input the audio file you want to transcribe and the desired output file format for the transcription of the audio. We currently support multiple input and output file formats.
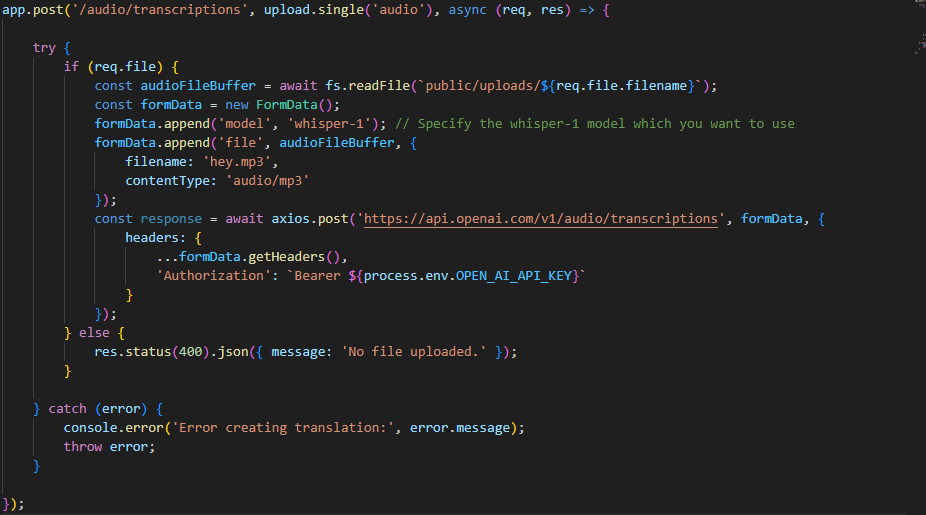
Step 1: Endpoint Definition
- This code handles a POST request to the /audio/transcriptions endpoint.
- The upload.single('audio') middleware is used to handle file uploads. It expects a single file with the field name 'audio' in the request.
Step 2: Try-Catch Block
- The code is wrapped in a try-catch block to handle potential errors that might occur during the process.
Step 3: File Upload Handling
- The code checks if a file was uploaded using if (req.file). If no file was uploaded, it sends a response with a 400 status code and a JSON message indicating that no file was uploaded.
Step 4: Reading File Content
- If a file was uploaded, it reads the content of the file using fs.readFile. The file content is stored in the audioFileBuffer variable.
Step 5: FormData Setup
- A FormData object named formData is created. This object is used to prepare the data to be sent in the HTTP request.
- The 'model' field is appended to the form data with the value 'whisper-1', which specifies the Whisper model to be used for transcribing the audio.
- The audio file content is appended to the form data using formData.append('file', audioFileBuffer, {...}). The {...} part provides additional metadata about the file, including the filename and content type.
Step 6: API Request
- An HTTP POST request is made to the OpenAI API using the axios.post method.
- The URL 'https://api.openai.com/v1/audio/transcriptions' is used to send the request.
- The formData object is sent as the data in the request body.
- Headers are set in the request, including the 'Authorization' header containing the OpenAI API key.
Step 7: Error Handling
- If an error occurs during the API request or any other part of the process, it is caught by the catch block.
- The error message is logged, and the error is thrown to be handled by higher-level error-handling mechanisms.
This code snippet essentially handles the process of uploading an audio file, preparing the data in a FormData object, and making an API request to the OpenAI service for transcribing the audio using the Whisper model.
To get OPEN API’s KEY
To obtain an OpenAI API key, follow these steps to integrate OpenAI's capabilities into your applications seamlessly. Start by visiting the OpenAI website and navigating to the "Pricing" or "API" section. There, you'll find information about the available subscription plans and pricing details. Choose the plan that best aligns with your project's requirements.

Upon selecting a plan, you'll be guided through the process of signing up and creating an account. This typically involves providing your email address, setting up a password, and verifying your account. Once your account is verified, you'll gain access to the OpenAI dashboard.
In the dashboard, you'll discover the section where you can generate your API key. This key serves as your access token, allowing your applications to interact securely with OpenAI's services. The dashboard might provide options to create, manage, and revoke API keys as needed.
Remember to handle your API key with care, as it's a valuable credential that grants access to OpenAI's services. You can then seamlessly integrate the API key into your projects, enabling them to harness the power of OpenAI's technologies, such as natural language processing and machine learning, to enhance your applications' functionality and capabilities.
Conclusion
Your journey to seamless Speech-to-Text experiences begins with the right talent. Embrace innovation, empower your applications, and enhance user engagement by hiring our skilled Node.js developers for Whisper API integration. Let's bring your ideas to life – start your voice-enabled transformation today!






